EASY AND AMAZING CONCEPT OF ARTIFICIAL INTELLIGENCE
Training
Weights start out as random values, and as the neural network learns more about what kind of input data leads to a student being accepted into a university(above example), the network adjusts the weights based on any errors in categorization that the previous weights resulted in. This is called training the neural network. Once we have the trained network, we can use it for predicting the output for the similar input.
Mean Squared Error is one of the popular error function. it is a modified version Sum Squared Error.

Or we can write MSE as:
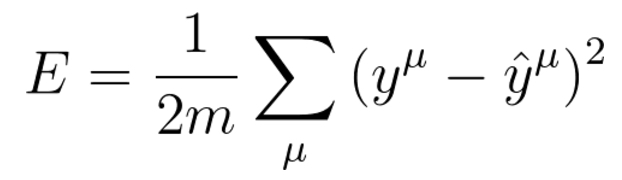
Forward Propagation
By propagating values from the first layer (the input layer) through all the mathematical functions represented by each node, the network outputs a value. This process is called a forward pass.
the parameters cannot be calculated analytically (e.g. using linear algebra) and must be searched for by an optimization algorithm.Gradient descent is used to find the minimum error by minimizing a “cost” function.
In the university example(explained it in the neural network section), the correct lines to divide the dataset is already defined. How does we find the correct line? As we know, weights are adjusted during the training process. Adjusting the weight will enable each neuron to correctly divide the dataset with given dataset.
To figure out how we’re going to find these weights, start by thinking about the goal. We want the network to make predictions as close as possible to the real values.
be in the direction that minimizes the error the most.
Back Propagation
In neural networks, you forward propagate to get the output and compare it with the real value to get the error. Now, to minimise the error, you propagate backwards by finding the derivative of error with respect to each weight and then subtracting this value from the weight value. This is called back propagation.
Before, we saw how to update weights with gradient descent. The back propagation algorithm is just an extension of that, using the chain rule to find the error with the respect to the weights connecting the input layer to the hidden layer (for a two layer network).
Regularisation
Regularisation is the technique used to solve the over-fitting problem. Over-fitting happens when model is biased to one type of datset. There are different types of regularisation techniques, I think the mostly used regularisation is dropout.
Optimisation
Optimisation is technique used to minimize the loss function of the network. There are different type of optimisation algorithms. However, Gradient decent and it’s variants are popular ones these days.

Comments